Code and Datasets
Featured
Codebases










CodeFormer


A blind face restoration algorithm for enhancing old photos and fixing AI arts.
View more
K-Net


A unified, simple, and effective framework to address semantic segmentation, instance segmentation and panoptic segmentation.
View more
Zero-DCE


Zero-Reference Deep Curve Estimation (Zero-DCE) formulates light enhancement as a task of image-specific curve estimation with a deep network. The method generalizes well to diverse lighting conditions.
View more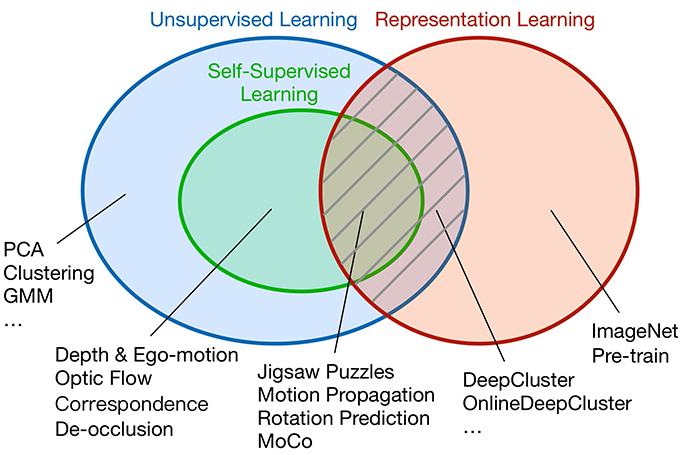
MMSelfSup


MMSelfSup, which was upgraded from OpenSelfSup, supports popular and contemporary self-supervised learning methods such as MoCo, MoCo v2, SimCLR, SwAV, ODC, BYOL, and SimSiam.
View more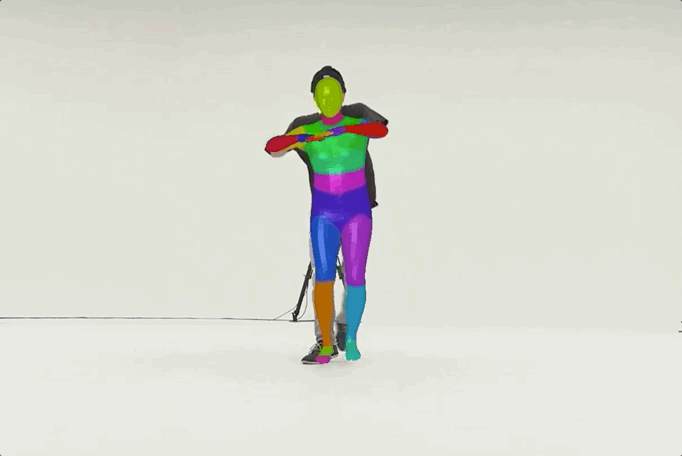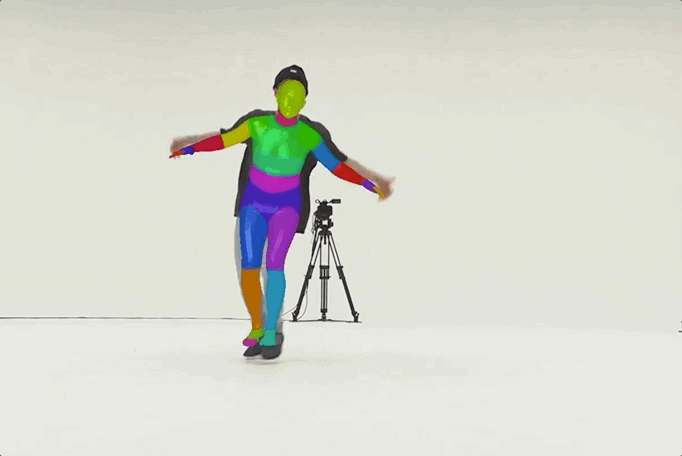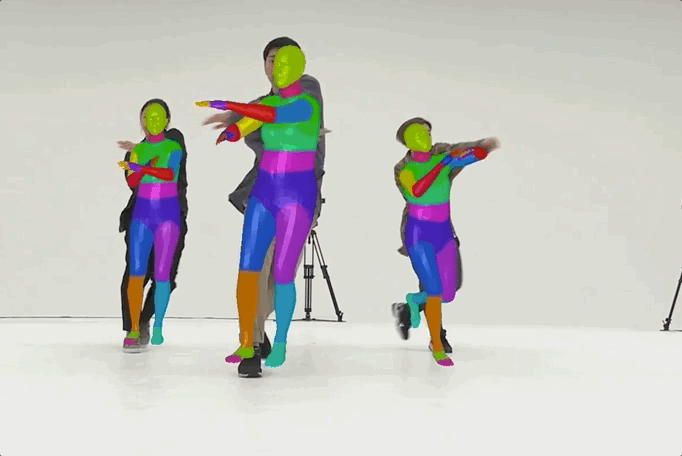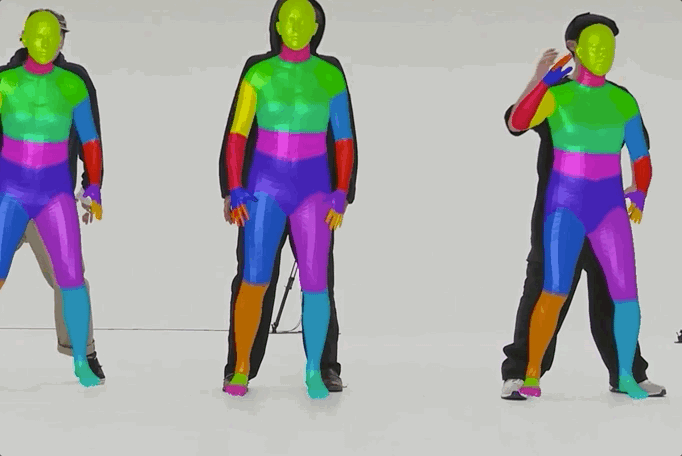
MMHuman3D


MMHuman3D is an open source PyTorch-based codebase for the use of 3D human parametric models in computer vision and computer graphics.
View more
MMDetection


MMDetection is an open source object detection toolbox that supports popular and contemporary detection frameworks, e.g., Faster RCNN, Mask RCNN, and RetinaNet. Easy-to-extend and highly efficient.
View more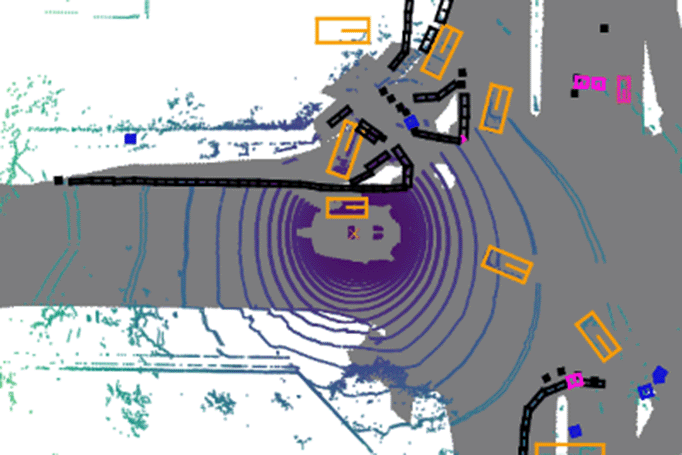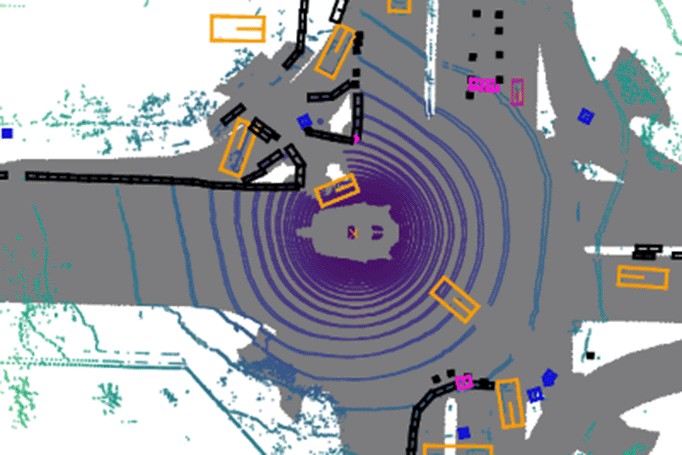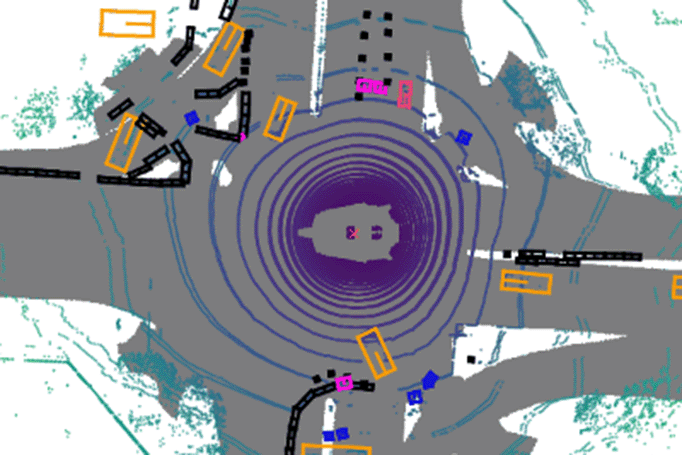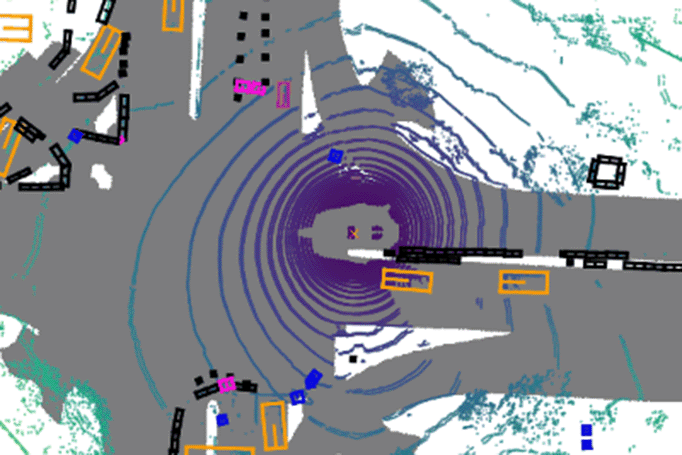
MMDetection3D


MMDetection3D supports multi-modality/single-modality 3D detectors out of box. It directly supports popular indoor and outdoor 3D detection datasets, including ScanNet, SUNRGB-D, Waymo, nuScenes, Lyft, and KITTI.
View more


OpenMMLab
As an open source project for academic research and industrial applications, OpenMMLab covers a wide range of libraries to facilitate research on various computer vision topics, e.g., classification, detection, segmentation and super-resolution. Join the OpenMMLab developer community to contribute, learn, and get your questions answered.
View moreFeatured
Datasets


OmniObject3D
OmniObject3D is a large vocabulary 3D object dataset with massive high-quality real-scanned 3D objects to facilitate the development of 3D perception, reconstruction, and generation in the real world.
View more
DNA-Rendering
DNA-Rendering presents a large-scale, high-fidelity repository of neural actor rendering represented by neural implicit fields of human actors.
View more
AnimeRun
AnimeRun is derived from 3D movies with pixel-wise and region-wise correspondence labels to facilitate research in 2D animation visual correspondence.
View more
Flare7K
Flare7K offers 5,000 scattering flare images and 2,000 reflective flare images for research in nighttime flare removal.
View more
LOL-Blur
LOL-Blur contains 12,000 low-blur/normal-sharp pairs with diverse darkness and motion blurs in different scenarios.
View more
StyleGAN-Human
SHHQ is a dataset with high-quality full-body human images in a resolution of 1024 × 512.
View more
CelebV-HQ
CelebV-HQ contains 35,666 video clips involving 15,653 identities and 83 manually labeled facial attributes covering appearance, action, and emotion.
View more
OmniBenchmark
OmniBenchmark is a diverse (21 semantic realm-wise datasets) and concise (realm-wise datasets have no concepts overlapping) benchmark for evaluating pre-trained model generalization across semantic super-concepts/realms.
View more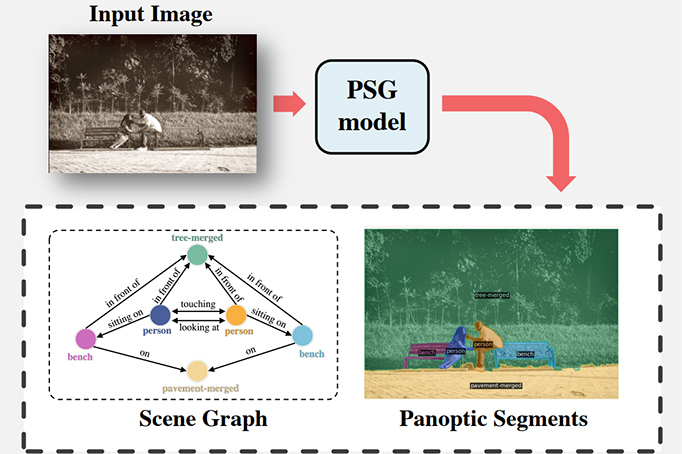
Panoptic Scene Graph
PSG dataset has 48749 images with 133 object classes (80 objects and 53 stuff) and 56 predicate classes. It annotates inter-segment relations based on COCO panoptic segmentation.
View more
GTA-Human
GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine, featuring a rich set of subjects, actions, and scenarios.
View more
CelebA-Dialog
CelebA-Dialog is a large-scale visual-language face dataset. Facial images are annotated with rich fine-grained labels. Each image comes with captions that describe its attributes and a sample of user request.
View more
ATD-12K
ATD-12K is a large-scale dataset that facilitates the training and evaluation of animation video interpolation methods. It contains 10,000 animation frame triplets and a test set of 2,000 triplets, collected from a variety of animation movies.
View more
MessyTable
A challenging dataset that features a large number of scenes with messy tables captured from multiple camera views. Each scene in this dataset is highly complex, containing multiple object instances that could be identical, stacked and occluded by other instances. The key challenge is to associate all instances given the RGB image of all views. Over 50K images with 1.2M bounding box annotations.
View more
Webly-Reference Super-Resolution
Webly-Reference SR dataset is a test dataset for evaluating reference-based super-resolution approaches. The dataset covers diverse categories including outdoor scenes, indoor scenes, buildings, famous landmarks, animals and plants.
View more
Under-Display Camera Images
Synthetic and real images for the research on under-display camera restoration. UDC systems introduce a new class of complex image degradation problems, combining flare, haze, blur, and noise.
View more
Multi-View Partial (MVP) Point Cloud Dataset
The dataset contains over 100,000 high-quality scans, obtained by rendering partial 3D shapes from 26 uniformly distributed camera poses for each 3D CAD model. For research on point cloud completion.
View more
NTURGBD-Parsing-4K
A multi-modality human perception dataset that contains i) diverse poses and actions, ii) both RGB and depth images, and iii) fine-grained human part parsing annotations.
View more
DeeperForensics
DeeperForensics is a large-scale face forgery detection dataset with 60, 000 videos constituted by a total of 17.6 million frames. Extensive perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework.
View more
ForgeryNet
The dataset contains 2.9 million images and 221,247 videos for the research of anti-deepfake. Manipulations are achieved using seven image-level approaches and eight video-level approaches. For the research on forgery detection.
View more